![NVIDIA RTX 4080 and 4090 to Launch in September 2022: Up to 2x More Performance than the RTX 3090 [Rumor]](https://www.teknogeeks.in/wp-content/uploads/2022/02/NVIDIA-RTX-4080-and-4090-to-Launch-in-September-2022-Up-to-2x-More-Performance-than-the-RTX-3090-Rumor.jpg-1170x658.png "NVIDIA RTX 4080 and 4090 to Launch in September 2022- Up to 2x More Performance than the RTX 3090-Rumor.jpg")
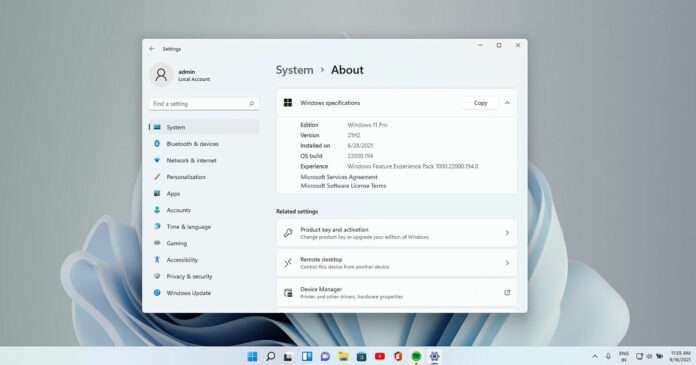
In the second half of the year, NVIDIA plans to release its next-generation RTX 40 series graphics cards. These GPUs will roughly double the raster and ray-tracing performance of existing RTX 30 “Ampere” parts, thanks to the Ada Lovelace microarchitecture and TSMC’s N5 (5nm) process node. According to reputable tipster Greymon55, NVIDIA will release its next generation of GeForce cards in September, beginning with the RTX 4080 and 4090.

The RTX 4080 is expected to have 16GB of GDDR6X memory running at around 21Gbps, while the RTX 4090 will have 20-30GB of GDDR6X memory. In terms of specifications, we’re looking at up to 18,432 FP32 cores. The flagship AD102 is said to have 144 SMs spread across 12 GPCs. Given that the core is running close to 2GHz, this results in a raw compute gain of over 2.5x (90 TFLOPs) over the GA102.
| GPU | TU102 | GA102 | AD102 | GH202 |
|---|---|---|---|---|
| Arch | Turing | Ampere | Ada Lovelace | Hopper |
| Process | TSMC 12nm | Sam 8nm LPP | TSMC 5nm | 3nm? |
| GPC | 6 | 7 | 12 | ~20 |
| TPC | 36 | 42 | 72 | ~140 |
| SMs | 72 | 84 | 144 | ~300 |
| Shaders | 4,608 | 10,752 | 18,432 | ~36,000? |
| TFLOPs | 16.1 | 37.6 | 90 TFLOPs? | 150 TFLOPs+ |
| Memory | 11GB GDDR6 | 24GB GDDR6X | 24GB GDDR6X | 32GB GDDR7? |
| Bus Width | 384-bit | 384-bit | 384-bit | 512-bit |
| TGP | 250W | 350W | 600W? | 600W+ |
| Launch | Sep 2018 | Sep 20 | Aug-Sep 2022 | 2024 |
The RTX 4080 and 4090 should have the same bus width as their predecessors (384 and 320 bits, respectively), but with faster GDDR6X chips, resulting in even more memory bandwidth. The Lovelace-based RTX 4070, RTX 4080, RTX 4090, and their brethren, according to Greymon55, will essentially be a miniaturization of their RTX 30 series predecessors on TSMC’s N5 (5nm) node.
On the top-end AD102 die, NVIDIA plans to increase the die size to nearly 900mm2 and pack over 18,000 FP32 ALUs or CUDA cores. Naturally, as more games adopt the technology, ray-tracing performance will receive special attention. To significantly improve RT capabilities, expect either a doubling of RT cores or some sparse matrix-grade optimization.












 is out with improvements")